



A Step-by-Step Guide to Building a Machine Learning Prediction Model
Machine learning has revolutionized the way data is used to make predictions and decisions. By leveraging powerful algorithms and computing power, machine learning models can be used to uncover patterns and insights from data that were previously impossible to detect. Building a machine learning prediction model can be a complex task, but with the right guidance and tools, anyone can create a model that can accurately predict outcomes. In this step-by-step guide, we will walk you through the process of building a machine learning prediction model, from data collection and processing to model training and testing. We will provide tips and techniques for each step to help you build a successful model. By the end of this guide, you will have the skills you need to create your own machine learning prediction model.
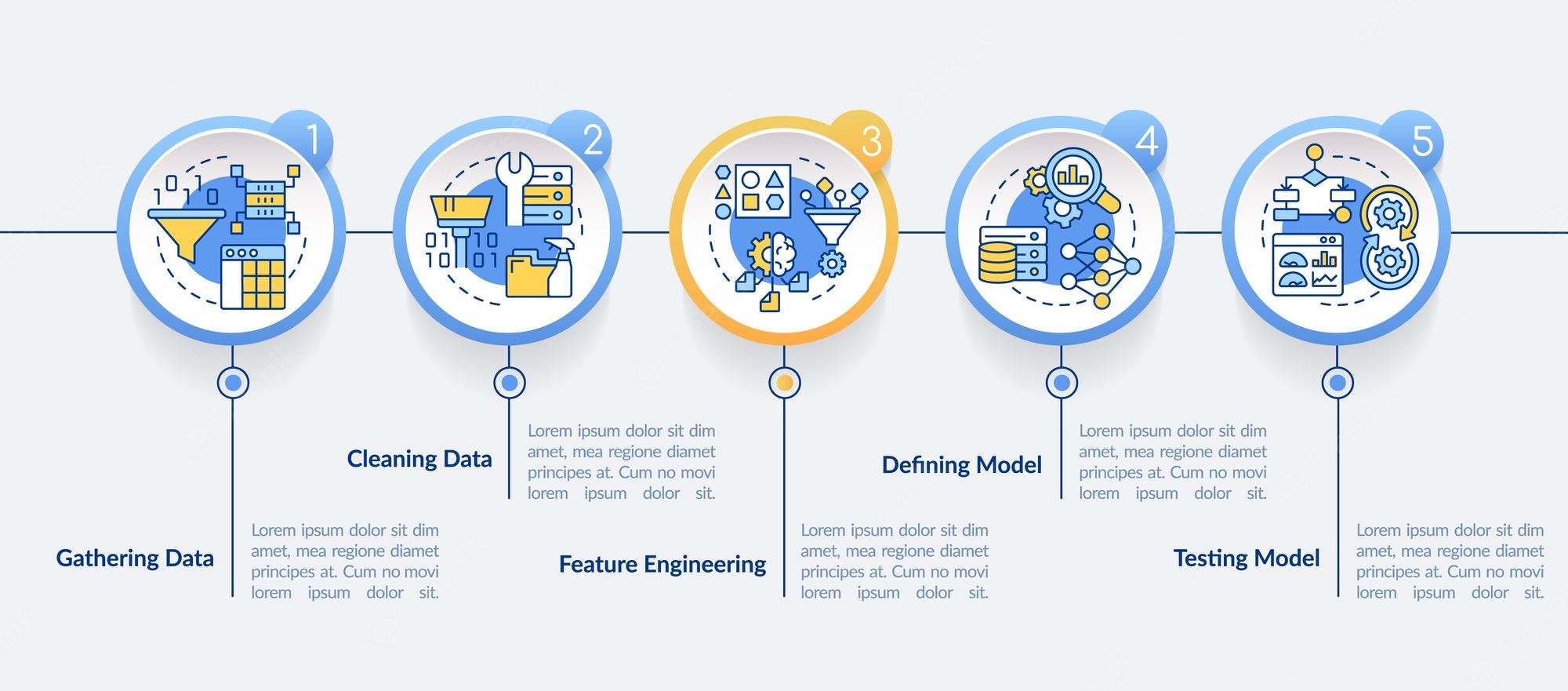
Data Collection and Pre-processing
The first step in building a machine learning model is to collect and prepare the data. Data is the fuel that powers machine learning models, and without high-quality data, you cannot build a high-quality model. There are several key considerations when collecting data for a model, including type and source of data, data format, and data volume. Before collecting data, you should determine how much data you need. While more data is always better, you need to ensure that collecting and pre-processing the data does not take longer than the model’s expected lifespan. Most machine learning models are built to make predictions for a specific timeframe. After that timeframe, the model’s accuracy will begin to degrade.
Feature Engineering
Once you have collected and prepared your data, you need to transform it into a format that can be used by the machine learning model. This is known as feature engineering, and it is an important part of the modeling process. There are three main considerations when feature engineering your data: univariate transformation, selection of relevant features, and transformation of categorical variables. Univariate transformation is the process of converting continuous variables, such as age and weight, into new categorical variables, such as age groups and weight groups. In most modeling scenarios, continuous variables are binned into groups to make them easier to use in the model. Selecting relevant features is important because the model will use these features to make predictions. You want to ensure that the features are relevant to your modeling scenario to avoid misleading predictions and false positives. Finally, transformation of categorical variables is important because machine learning models perform better with categorical variables than with raw numbers.
Model Selection
Once you have selected the data you want to use and transformed it into the format needed by the model, you need to select the appropriate model. A wide variety of machine learning models can be used to solve a wide variety of problems. The first step in selecting a model is determining which type of model you want to use. There are three main types of machine learning models: These three models each have unique strengths and weaknesses, and each model can be used to solve a variety of problems. Once you have selected a model type, you need to identify the best model for your specific problem. The model with the highest accuracy does not always win. You need to assess the model’s error rate, the interpretability of the model, and the time needed to train the model. In some cases, it may be better to use a model with a lower accuracy rate if it has a lower error rate, provides better insights, or can be trained faster.
Model Training
After you have selected the model and prepared the data, you are ready to train the model. During training, the model is given the prepared data along with the expected outcomes. The model uses this data to uncover patterns and make predictions. While there are many techniques for training a machine learning model, most models are either trained using an online or offline approach. Online models use parallel processing and can be used to predict multiple outcomes in near real time. Offline models use serial processing and can be used to make predictions offline. The best approach to use depends on the model and the problem being solved. While there are many different techniques for training a machine learning model, there are three key considerations that should be evaluated during each training session. The first consideration is model accuracy. You want to ensure that the model is accurately uncovering patterns and making accurate predictions. You can use a variety of metrics, including accuracy, ROC, and AUC, to ensure that the model is performing well. The second consideration is model bias and variance. Bias is the tendency of the model to consistently predict a specific outcome. Variance refers to the range of values the model is predicting. You want to ensure that the model is neither too biased nor too inconsistent.
Model Evaluation
After the model has been trained, you can evaluate the accuracy of the model by testing it against a holdout dataset. A holdout dataset is a portion of the data that was not used during training. The model can be tested against a new, completely unrelated dataset to determine how well it generalizes. There are three key considerations when evaluating the model. The first consideration is model accuracy. You want to ensure that the model is accurately predicting the outcomes in the holdout dataset. You can use a variety of metrics, including accuracy, ROC, and AUC, to ensure that the model is performing well. The second consideration is model variance. You want to ensure that the model is not too inconsistent. You can use a model’s standard deviation and coefficient of variation to determine how consistent the model is. The third consideration is model interpretability. You can use a variety of techniques to assess model interpretability, including t-tests and R2 values.
Model Deployment
After you have selected the model and trained it, you are ready to deploy it. There are many considerations when deploying a machine learning model, including model type, cost, and maintenance requirements. You also need to consider who will use the model and how it will be deployed. Once you have selected the model type, you can use that model to solve a variety of problems. If you follow these steps, you will have the skills you need to create your own machine learning prediction model. With dedication, you can create a model that can make accurate predictions and transform any industry.